Lecture 3 - Andrej Karpathy's course
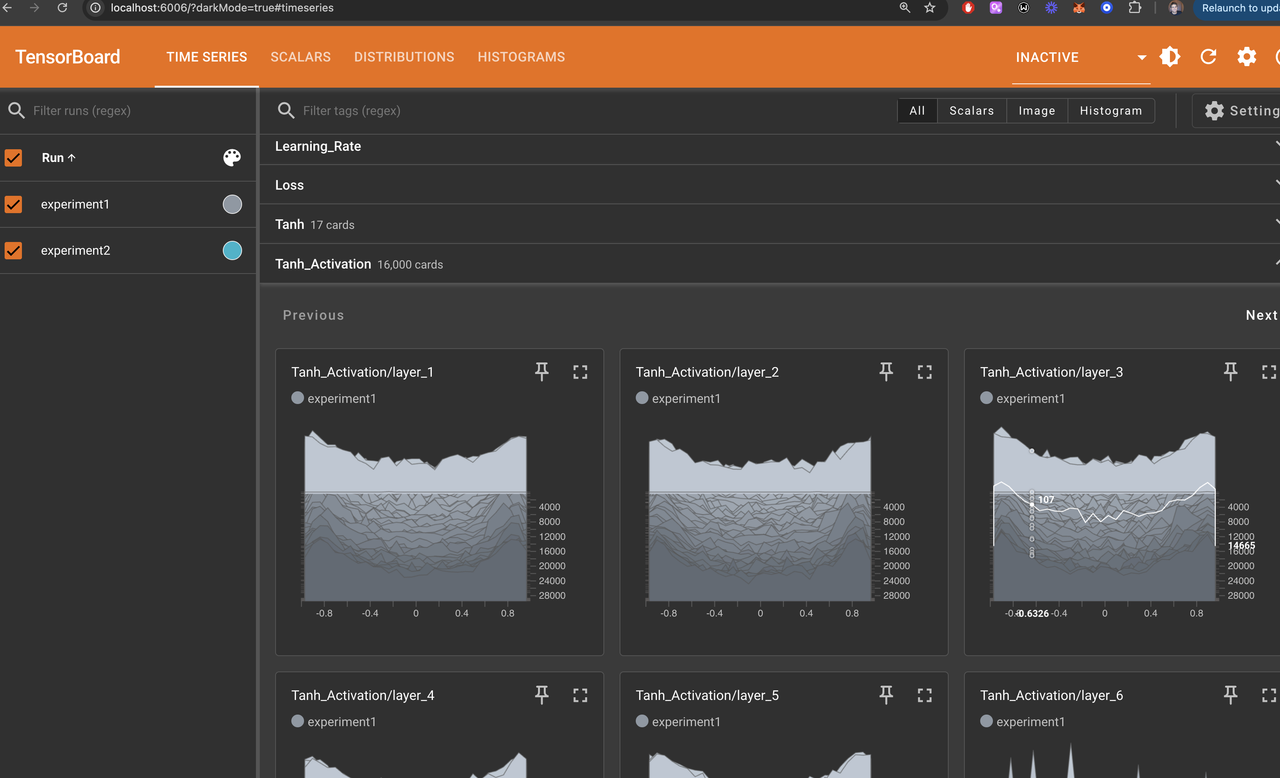
Below you can find the notebook I used for lecture 3 (original notebook). I decided to PyTorchify the neural net definition and training, since I thought this would be more production-ready and a great opportunity for me to get my hands dirty with PyTorch. Specially useful here was to use Tensorboard for visualizing tanh activations (which should be not too far away from the middle otherwise it kills the gradient backpropagation).
During the lecture, additional statistics are collected (e.g. gradient absolute value w.r.t. data value, which should be ~ 1e-3 * data value as an heuristic), but I assume this will be part of next lectures thus not tracking all of that here.
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import random
%matplotlib inline
import requests
32033 emma
# initialize datasets
n1 = int(0.8*len(words))
n2 = int(0.9*len(words))
Xtr, Ytr = utils.build_dataset(words[:n1])
Xdev, Ydev = utils.build_dataset(words[n1:n2])
Xte, Yte = utils.build_dataset(words[n2:])
class MyMLP(nn.Module):
def __init__(self, vocab_size, n_embd, block_size, n_hidden):
super().__init__()
#self.embedding = nn.Embedding(vocab_size, n_embd),
self.net = nn.ModuleList([
#nn.Parameter(torch.randn((vocab_size, n_embd), generator=g)),
nn.Linear(n_embd * block_size, n_hidden, bias=False),
nn.BatchNorm1d(n_hidden),
nn.Tanh(),
nn.Linear(n_hidden, n_hidden, bias=False),
nn.BatchNorm1d(n_hidden),
nn.Tanh(),
nn.Linear(n_hidden, n_hidden, bias=False),
nn.BatchNorm1d(n_hidden),
nn.Tanh(),
nn.Linear(n_hidden, n_hidden, bias=False),
nn.BatchNorm1d(n_hidden),
nn.Tanh(),
nn.Linear(n_hidden, n_hidden, bias=False),
nn.BatchNorm1d(n_hidden),
nn.Tanh(),
nn.Linear(n_hidden, vocab_size, bias=False),
nn.BatchNorm1d(vocab_size),
])
self.tanh_layers = [layer for layer in self.net if isinstance(layer, nn.Tanh)]
self.tanh_activations = [None] * len(self.tanh_layers)
def forward(self, x):
activation_index = 0
for layer in self.net:
x = layer(x)
if isinstance(layer, nn.Tanh):
# Retain the graph for non-leaf Tensors to access their gradients
x.retain_grad()
self.tanh_activations[activation_index] = x
activation_index += 1
return x
def log_tanh_stats(self, writer, step):
for i, act in enumerate(self.tanh_activations):
if act is not None and act.requires_grad:
writer.add_histogram(f"Tanh/layer_{i+1}/activation", act.detach().cpu(), step)
if act.grad is not None:
writer.add_histogram(f"Tanh/layer_{i+1}/gradient", act.grad.detach().cpu(), step)
# Now we build the layers using Pytorch
n_embd = 10 # the dimensionality of the character embedding vectors
block_size = 3
n_hidden = 100 # the number of neurons in the hidden layer of the MLP
g = torch.Generator().manual_seed(2147483647)
# We replace torch.randn by nn.Parameter so that Pytorch tracks gradients automatically
C = nn.Parameter(torch.randn((vocab_size, n_embd), generator=g))
layers = MyMLP(vocab_size, n_embd, block_size, n_hidden)
# Loss function and optimizer
parameters = list(layers.parameters())
for p in parameters:
p.requires_grad = True
#optimizer = torch.optim.SGD(parameters, lr=0.001)
# I am cheating below because Andrej doesn't use Adam, rather SGD.
optimizer = torch.optim.AdamW(parameters, lr=1e-3)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10000, gamma=0.5)
loss_fn = nn.CrossEntropyLoss()
num_iterations = 10000
batch_size = 32
for step in range(num_iterations):
# Sample a batch of data
ix = torch.randint(0, Xtr.shape[0], (batch_size,), generator=g) # example input: indices of tokens
Xb, Yb = Xtr[ix], Ytr[ix] # input and target batches
# forward pass
emb = C[Xb]
x = emb.view(emb.shape[0], -1)
out = layers(x)
# Loss
loss = loss_fn(out, Yb) # compute the loss
loss_value = loss.item()
#loss = F.cross_entropy(x, Yb) # loss function
# Backward pass
optimizer.zero_grad() # zero the gradients
loss.backward() # compute gradients
optimizer.step() # update weights
scheduler.step()
# logging loss
writer.add_scalar("Loss/train", loss_value, step)
writer.add_scalar("Learning_Rate", optimizer.param_groups[0]["lr"], step)
# Log Tanh layer statistics
layers.log_tanh_stats(writer, step)
if step % 1000 == 0 or step == num_iterations - 1:
current_lr = optimizer.param_groups[0]["lr"]
print(f"Step {step + 1}/{num_iterations}, Loss: {loss.item():.4f}, LR: {current_lr:.6f}")
writer.close()
/var/folders/yp/9rxjv3w91p3b3kh1v7prxz600000gn/T/ipykernel_32808/1206273740.py:48: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/build/aten/src/ATen/core/TensorBody.h:494.)
if act.grad is not None:
Step 1/10000, Loss: 3.5513, LR: 0.001000
Step 1001/10000, Loss: 2.3467, LR: 0.001000
Step 2001/10000, Loss: 2.6509, LR: 0.001000
Step 3001/10000, Loss: 2.3917, LR: 0.001000
Step 4001/10000, Loss: 2.0545, LR: 0.001000
Step 5001/10000, Loss: 2.3273, LR: 0.001000
Step 6001/10000, Loss: 1.8819, LR: 0.001000
Step 7001/10000, Loss: 2.4040, LR: 0.001000
Step 8001/10000, Loss: 2.5658, LR: 0.001000
Step 9001/10000, Loss: 2.2533, LR: 0.001000
Step 10000/10000, Loss: 2.1536, LR: 0.000500
@torch.no_grad() # this decorator disables gradient tracking
def split_loss(split):
x,y = {
'train': (Xtr, Ytr),
'val': (Xdev, Ydev),
'test': (Xte, Yte),
}[split]
layers.eval()
emb = C[x] # (N, block_size, n_embd)
embcat = emb.view(emb.shape[0], -1) # concat into (N, block_size * n_embd)
logits = layers(embcat)
loss = loss_fn(logits, y)
print(split, loss.item())
layers.train() # optional: switch back to training mode
split_loss('train')
split_loss('val')
split_loss('test')
train 2.1556262969970703
val 2.388932943344116
test 2.4112343788146973
Another goal of the lecture was to track statistics of training using Tensorboard. Nowadays there are more advanced alternatives (like MLFlow), but getting started with Tensorboard for now. See the screenshot for tanh activations.